virtio-blk vs virtio-scsi
23 Jan 2017Introduction
KVM and QEMU support two paravirtualized storage backends: the older virtio-blk and more modern virtio-scsi. Fully emulated devices are not in scope of this post as their performance is subpar1 and shouldn’t be used except for compatibility purposes – like CD-ROMs. We won’t focus on the fine grained difference between virtio-blk and virtio-scsi. Why? You can find multiple benchmarks and comparisons online234. The idea is to go over the high-level difference between the backends as our main focus is to determine the suitability in enterprise deployments managed by oVirt.
How is virtio-blk different from virtio-scsi? Let’s begin with the architecture.
virtio-blk:
guest: app -> Block Layer -> virtio-blk host: QEMU -> Block Layer -> Block Device Driver -> Hardware
virtio-scsi (using QEMU as SCSI target):
guest: app -> Block Layer -> SCSI Layer -> scsi_mod host: QEMU -> Block Layer -> SCSI Layer -> Block Device Driver -> Hardware
As you can see, virtio-scsi is slightly more complex. We will assume that the complexity itself will have some performance impact that will be proportional to IO depth – higher IO depth could “mask” the stack overhead.
Node Naming
This is where things get interesting. Major user facing difference is actual device node name: virtio-blk names devices /dev/vd[a-z]+ whereas virtio-scsi uses widespread /dev/sd[a-z]+ naming. There is more benefit than just having “modern, admin-friendly” names. In v2v and p2v situations, /dev/sd[a-z]+ naming can be preserved. In cases where we do change name from /dev/vd[a-z]+ to /dev/sd[a-z]+, known parts of the OS can be changed. Custom scripts that rely on device node names can break (but such scripts should’ve used /dev/disk/by-uuid in the first place).
Maximum Number of Devices
virtio-blk links PCI and storage devices in a 1:1 relationship, or in other words – each disk is accompanied by a PCI device. The PCI bus is limited to 32 devices. Based on these facts5, we can define the maximum number of virtio-blk devices as (32 - #ovirt_default_devices) where #ovirt_default_devices are superset of QEMU default devices. Using 4.2 master branch of oVirt, we have 11 PCI devices by default (12 if virtio-scsi disk is used). Using the equation, we get $32 - 11 = 21$ available virtio-blk slots.
virtio-scsi also has limited total number of available drives. The virtio-scsi controller can have up to 256 “targets”, and each target can have up to 16,384 “LUNs” – or what we consider drives. The theoretical limit is therefore 4194304 LUNs per controller. Browsing through kernel history, the limit was once set to $26 + 26 ^ 2 + 26 ^ 3 = 18278$ LUNs, but the limitation has been lifted6. The question “how many LUNs really are supported” is left as an exercise. :)
Performance
As per previous assumption, virtio-scsi is expected to perform slightly worse in low IO depth workloads, while increasing IO depth could mask the SCSI stack complexity. We will also look at respective performance with IO threads enabled, trying to find whether using IO threads by default could offset the current performance difference. The tests were run on workstation with following configuration (relevant parts):
- Intel Xeon E5-2650 v3
- Intel I210 NIC (1 gbps)
- 64 GiB ram
And VM:
- 10 GiB ram
- 8 vCPUs
- virtio NIC
- 9 disks from storage array (SSD based) connected via NFS
Although the setup is far from perfect for proper testing (cough using office network as a connection to the storage array, NFS etc.) it should be able to give us enough data to compare the two storage interfaces. We are not testing the disks theoretical limits by any means.
The tool to measure IO performance is fio (flexible I/O tester). The fio file varied between randrw/randwrite/randread and iodepth, but the general design can be seen below.
[global]
size=2g
thread=1
ioengine=libaio
direct=1
buffered=0
bs=4k
[drive1]
filename=/dev/sdb
[drive2]
filename=/dev/sdc
[drive3]
filename=/dev/sdd
[drive4]
filename=/dev/sde
[drive5]
filename=/dev/sdf
[drive6]
filename=/dev/sdg
[drive7]
filename=/dev/sdh
[drive8]
filename=/dev/sdiThe tests are in following order:
- randread, iodepth=1
- randread, iodepth=4
- randread, iodepth=8
- randrw (25 % writes), iodepth=1
- randrw (25 % writes), iodepth=4
- randrw (25 % writes), iodepth=8
- randrw (50 % writes), iodepth=1
- randrw (50 % writes), iodepth=4
- randrw (50 % writes), iodepth=8
- randrw (75 % writes), iodepth=1
- randrw (75 % writes), iodepth=4
- randrw (75 % writes), iodepth=8
- randwrite, iodepth=1
- randwrite, iodepth=4
- randwrite, iodepth=8
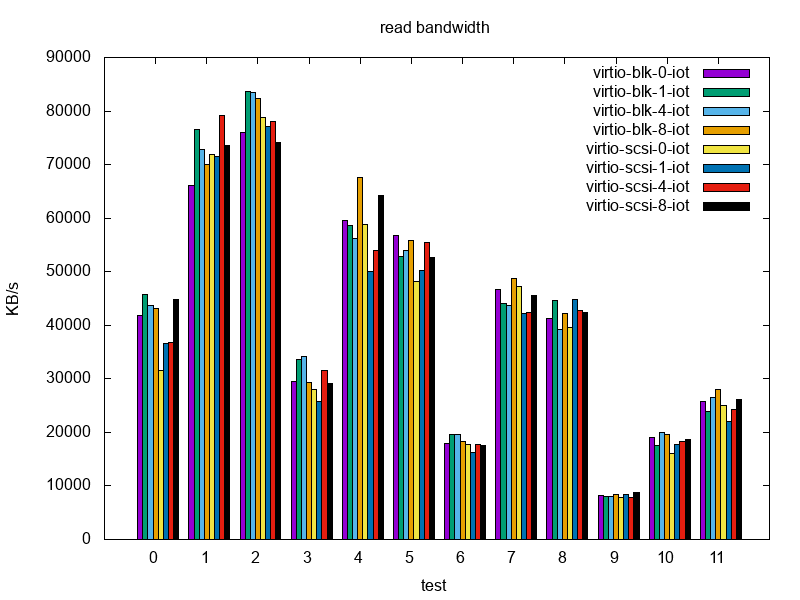
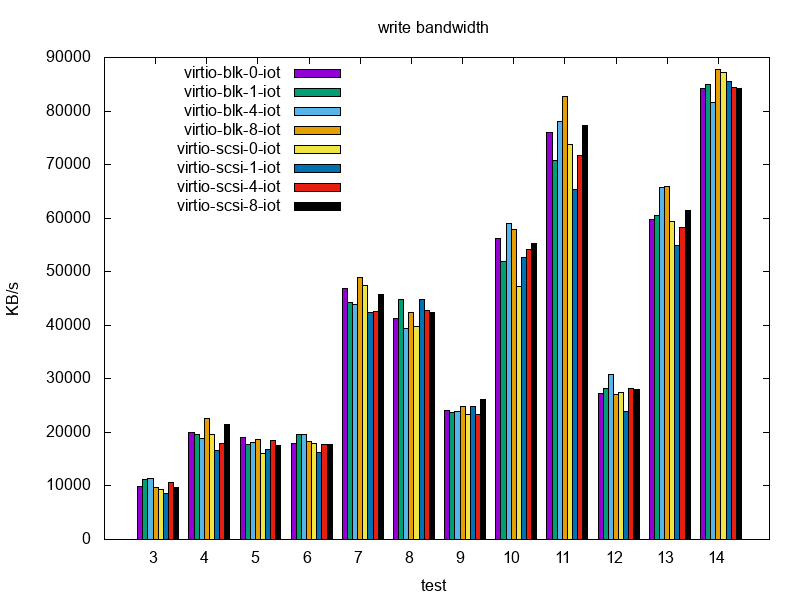
The read performance for the first 3 (randread) tests is slightly in favor of virtio-blk. In the low IO depth scenario without IO threads, virtio-scsi seems to deliver only ~75 % of the virtio-blk read performance. As the IO depth increases, virtio-scsi without IO threads delivers slightly broader read bandwidth. On the other hand, virtio-blk seems to scale well with IO threads in scenarios where IO depth is 4 and 8.
In the next 3 (randrw, 25 % writes) tests, virtio-blk stays ahead even in higher IO depth scenarios with a higher read performance and just a slightly higher write performance.
Moving up to more write-intensive (randrw, 50 % writes), the results are mixed – IO thread scaling is mostly visible in (IO depth = 4 scenario, IO threads = 8) and (IO depth = 8, IO threads = 4) cases. That being said, virtio-scsi (without IO threads) delivers almost the bandwidth of virtio-blk with 8 IO threads in IO depth = 4 case.
Interesting.
In write-intensive workloads (randrw, 75 % writes) virtio-blk stays ahead by at least 5 % for read bandwidth. The virtio-blk write bandwidth shows an improvement between 2 % and 25 %.
Write-only tests were done for completeness and show no significant performance difference.
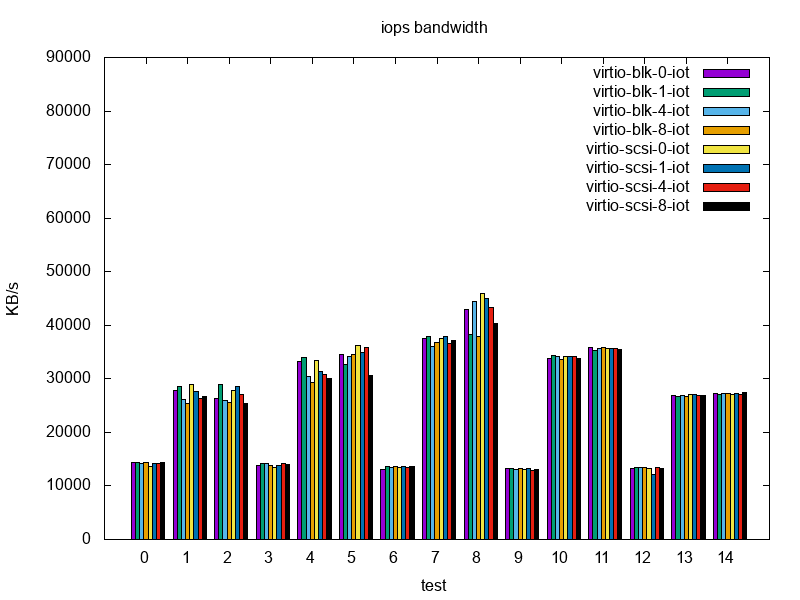
When it comes to IOPS, randread in low IO depth case shows a slight drop for virtio-scsi without IO threads, but remains close throughout the other cases. As IO depth increases, virtio-scsi takes the lead. When mixing writes with reads (25 %, 50 %), virtio-scsi is either the leader or in the worst case within few % of virtio-blk. As we add IO threads, IOPS are dropping. Randwrite doesn’t have any statistically significant impact.
In summary, virtio-scsi is performing slightly worse than virtio-blk. However as expected, it is slowly catching up in high IO depth scenarios. My conclusion is that there is no default for the number of IO threads that would be generally optimal. To maximize the performance, users would have to benchmark with regards to their workloads and derive the best configuration from that.
Features
At the moment, a key difference is the BLKDISCARD capability, supported by virtio-scsi. BLKDISCARD is an ioctl, that discards blocks on a device – for example using ATA TRIM command on modern SSDs. virtio-blk does not support it and probably never will. As for other potential features, they will most likely be implemented in virtio-scsi first. Due to the complexity of extending virtio-blk it is questionable that any new features will ever be added.
EDIT
BLKDISCARD support was added in this qemu patch (22 Feb 2019). Never say never I guess.
Conclusions
Looking at the advantages of virtio-scsi, I believe it’s the correct choice as a default VM disk interface in oVirt. For optimized VMs, there is always the choice of manually switching to virtio-blk (or IDE, if you’re optimizing for slowness… or compatibility). For now, adding IO thread may cause more harm than good, therefore we’ll leave that for the future.